Gibson Assembly 可以一次实验组装多段已有的 DNA。
本文仅介绍已公开的生物工程技术的原理,不涉及具体的实验操作步骤。进行生物实验之前,须完成和实验室生物安全等级匹配的培训。
作为一种黑箱
Gibson Assembly 可以一次实验组装多段已有的 DNA。
对于常用且简单的,把 2 段 DNA 分子组合成环形 DNA(通常是质粒)的情况:
输入
- 双链 DNA 片段 A
5'--> A -->3' - 双链 DNA 片段 B
5'--> B -->3'
参数
- A 的正向引物:(B序列的末尾若干碱基 + A序列的开头若干碱基)
- A 的反向引物:(A序列的末尾若干碱基 + B序列的开头若干碱基)的反向互补序列
- B 的正向引物:(A序列的末尾若干碱基 + B序列的开头若干碱基)
- B 的反向引物:(B序列的末尾若干碱基 + A序列的开头若干碱基)的反向互补序列
输出
- 环形双链 DNA
5'--> A -->3'
| |
3'<-- B <--5'
黑箱之内
预备知识
DNA 大分子的单体是脱氧核苷酸。脱氧核苷酸分子由磷酸基、脱氧核糖、碱基通过共价键连接形成,磷酸基连接在本分子的脱氧核糖的 5’ 号碳原子上。
单链 DNA 分子由脱氧核苷酸分子脱水缩合形成,后一个脱氧核苷酸的磷酸基团连接到前一个的脱氧核糖的 3’ 号碳原子上。单链是有方向的,习惯上定义为从 5’ 指向 3’ 端。
两条碱基序列足够匹配的单链 DNA 分子,配对的碱基之间通过氢键连接,形成双链 DNA 分子。双链分子中的两条单链的方向相反。
描述一段双链 DNA 的序列时,约定俗成选一条链作为主链,然后从 5' 到 3' 端读出它的序列。
比如当我们说一段双链 DNA 的序列是 AGCTGCTCTT 时,指的实际上是这样一个分子:
5'-A-G-C-T-G-C-T-C-T-T-3'
| | | | | | | | | |
3'-T-C-G-A-C-G-A-G-A-A-5'
把下面那条单链的序列从右往左读 AAGAGCAGCT 叫做原序列的反向互补 (reverse complement)(对它本身来说也是从 5’ 到 3’ 读。)
PCR 构造重合区间
Gibson assembly 的开头通常是一种特殊的 PCR,通过设计引物 (primer),给 A 和 B 分子的两端分别加上对方的一点序列:
文章开始时说的输入和参数如下:
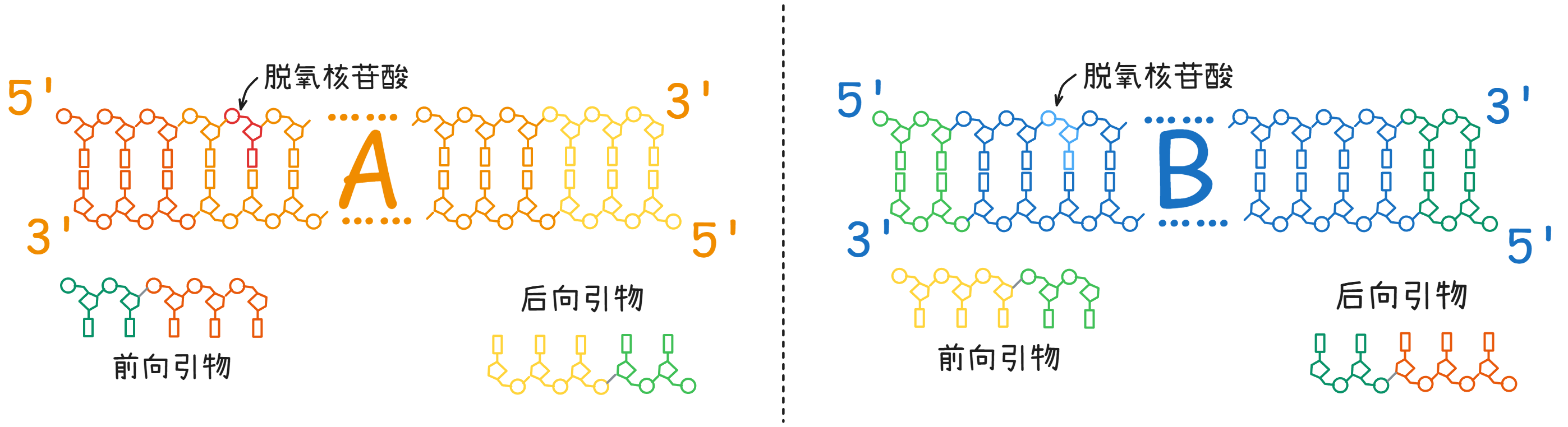
PCR 的第一个循环:
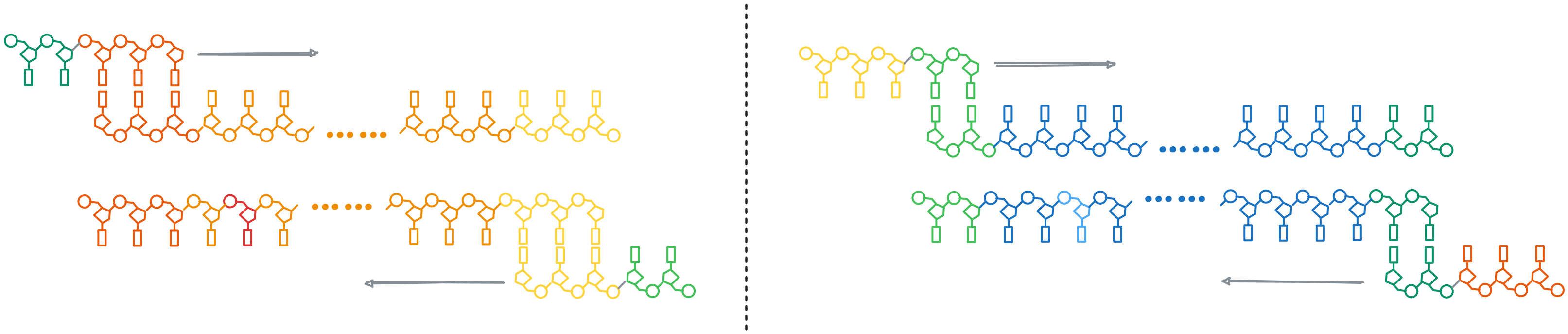
第一个循环的结果是两种带有悬空核苷酸的双链 DNA:
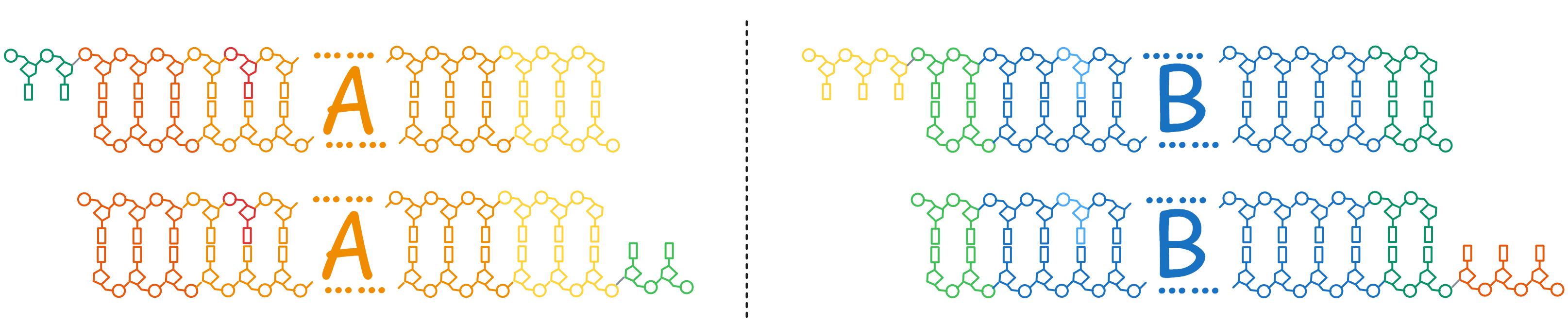
PCR 的第二个循环中,最符合我们需要的情况:
结果:
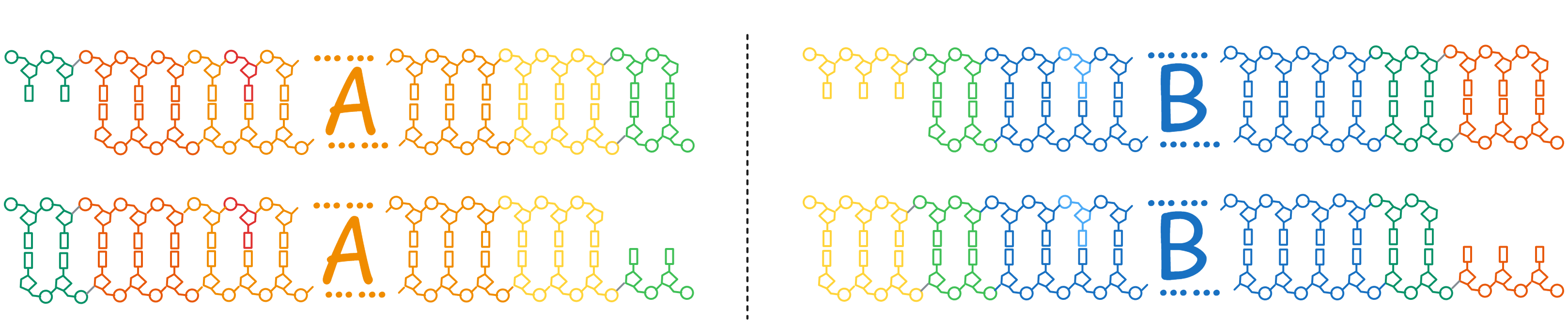
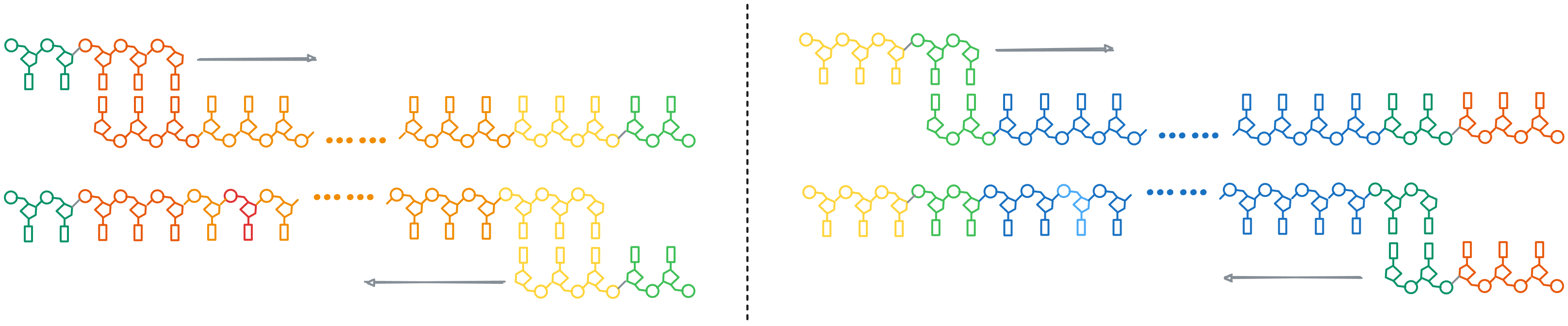
PCR 的第三个循环:

开始出现我们的最终产物:

ChatGPT 说,设计引物的熔融温度时,应只根据和最初模板配对的部分计算,不考虑在最初循环时悬空在外的那半截。
组装过程
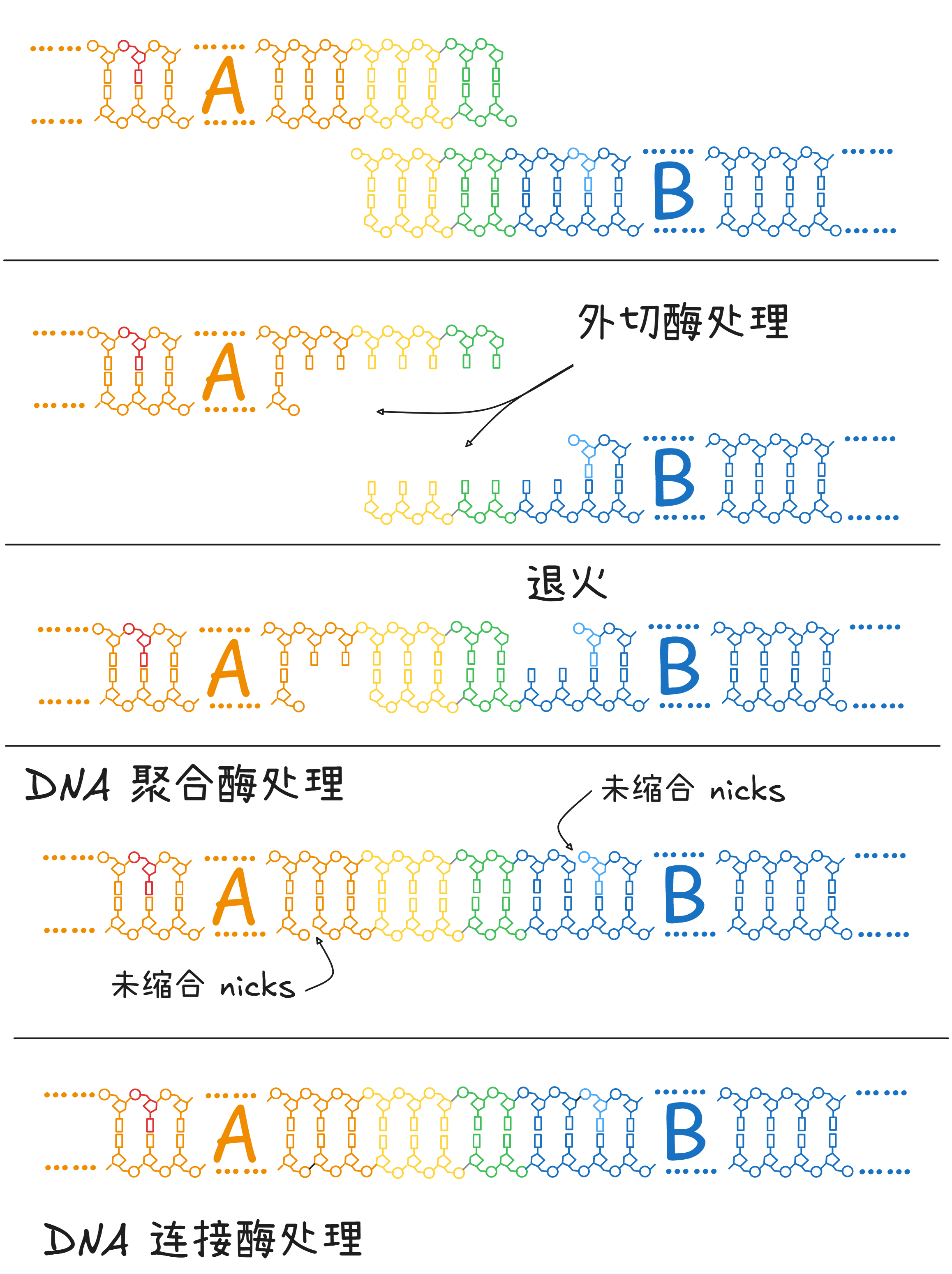
有了重合序列之后,以下各步一个试管一次反应就可完成:
- 外切酶从两个序列的 5’ 端开始降解若干核苷酸;
- 两序列退火,重合区的碱基互补配对
- DNA 聚合酶补上第 1 步多切掉的核苷酸
- DNA 连接酶补上最后一个 3’,5’-磷酸二酯键。
本文收录于以下合集: