“什么是智能”的问题每每得不到回答,是因为它的逆问题“智能是什么”没有答案。
0
这是一篇酬和之作。
徵文标题说的是:
機器會製造「內涵」嗎?
但是正文提出的问题是:
AI透過程式組合出回答你問題的文字組合,有「涵義」嗎?
可是,「內涵」和「涵義」两个词的——内涵/涵义——就不完全一样啊……
“内涵”(connotation) 通常指词语或表达方式所隐含的情感、态度、暗示或附加的意义。它涉及到词语或表达方式所引起的情感、联想或隐含的观点。也就是弦外之音。
而“涵义”(meaning) 一般指词语、表达方式或行为所传达的字面意义或字面上的定义。它强调的是直接的、明确的意义。
看热闹不嫌事大,那我们再把问题搞复杂一点——在逻辑学里也有一个“内涵”(intension),和“外延”(extension) 相对应。用面向对象编程的说法来理解,一个类里面定义的所有状态量和内部方法的集合,就构成这个类的“内涵”;所有(已经和将来能够)从这个类实例化出来的对象的集合,就构成这个类的“外延”。
所以看起来,征文者想问的是日常“内涵”也就是言外之意,但是怕杠精(比如我)用有严格定义的逻辑“内涵”解构掉,所以换了“涵义”一词。
这个问题很显然是因应最近大语言模型掀起的这一波 AI 浪潮。这个问题往前再问一句,就是“大语言模型是智能体/有智能吗?”
- 前两年 DeepMind 的 AlphaGo/AlphaZero 系列 AI 在围棋中击败人类棋手时,人们也在问这个问题。
- 上世纪四五十年代专家系统 (expert system) 刚刚开发的时候,人们也在问这个问题。
- 从电子计算机往前追溯到机械计算机,甚至是巴比奇的差分机的时候,人们就已经开始问这样的问题了。
这些问题求并集,然后在问题数量趋近于无穷下的极限,就是“什么是智能”。
这样的问题每每得不到回答,是因为它的逆问题“智能是什么”没有答案。我们并没有智能的准确定义,只能一事一论。而之前的智能和非智能体的区别太明显,以至于作出判断也不能对智能的定义有所启发。
1
而对“智能是什么”的探究,哲学、逻辑学、计算机科学、生物学、管理学,不同领域的研究者有着不同的思路。
古哲学·洞穴之壁与理念世界
古希腊哲学家柏拉图在《理想国》里提到了“洞穴之壁”的寓言故事。
有一群被囚禁在一个深洞的囚徒,从出生开始就被束缚在这个洞穴里,脖子和腿都被铁链锁住,没办法转身或离开。囚徒身后的洞穴入口处有一道火焰,火焰后有人持物体走过,物体的投射在洞穴内的墙壁上形成了影子。囚徒们就以为这些影子就是唯一的存在。
这里的囚徒代表着人类,洞穴代表着世界,影子则代表着我们对于现象世界的感知和观念。人们的知识和信念往往受限于自己的经验和感知,就像囚徒们只看到了洞穴墙壁上的影子,而在影子之外还存在一个理想的理性世界。柏拉图用这个寓言故事表达了他对于人类认识和智慧的理解。所谓智慧,就是从洞穴的影子反过去推测火把前物体的能力。
当然,这种思想被 Marx 主义定性为一种客观唯心主义、唯理论,是受其批判的。
逻辑学·从命题到希尔伯特算符
柏拉图的学生亚里士多德,今天在低年级的物理教科书里基本是个反面典型,但他对逻辑学进行了系统化和全面的研究,提出了许多逻辑学的基本概念和原理。这些成果后来成为了欧洲哲学和逻辑学的基石,对西方哲学和科学的发展产生了深远影响。
所谓逻辑,就是研究命题的对错,以及如何判断命题对错的学问。而命题,就是能被判断对错的句子。但是句子显然可以再分成不同成分,于是就发明/发现了主体、客体、谓词、谓词的量词……等等概念,以及用这些概念构造命题的方法。
但是要注意,虽然逻辑主要由语言来表达,但是逻辑还是和语言不同,主体、客体也不等于句子的主语、宾语。这两者的区别,基本可以类比于之前洞穴之壁寓言里的实体和影子。
这种努力到目前为止的巅峰,基本上要数希尔伯特形式化逻辑系统了。感兴趣的朋友可以自行查阅戈得门特《代数学教程》的第一章,这玩意相当于思想界的引体向上,反正我是一个也拉不上去……
计算机·从半导体到抽象语法树
希尔伯特是德国的数学家,《代数学教程》也是数学而不是哲学教材。显而易见,逻辑虽然由哲学家奠基,但是主导权很快落到数学家,至少是哲学家兼数学家手里了。
命题的“真”与“非真”同构于 {1, 0},各种逻辑运算都可以分解成“或”与“非”两种基本逻辑运算的组合,这就是以数学家乔治·布尔 (George Boole) 命名的布尔代数。因为 {1, 0} 又可以同构于半导体电路的高低电位,和各种类似继电器的门电路组合,所以很容易用计算机在物理世界表示出这些逻辑运算。
我们的电脑由上亿个这样的电位和逻辑门组成,一般的科普文章应该会去介绍芯片啊光刻机之类的东西,本文关注的是另一个方面:虽然生产电脑配件的厂商很多,不同的型号的元器件设计不同,组装出的成品应该千差万别,但是他们可以运行同样的程序,理想条件下(虽然实际工程中常常不理想)我们也可以期望他们跑出同样的结果。
这说明所谓计算机科学,并不等同于研究计算机元件的电子科学和工程,这里电科和电子工程相当于洞穴岩壁上的影子,而计算机科学就相当于火光前的物体。这种超越物理的计算本质,一般用一种叫做“抽象语法树”的数据结构来表示。
生物学·从神经元到神经网络
人们发明计算机的时候,基本上还是把它当作工具,就没期望它有什么主体性和智慧。
而随着生物学逐渐发现了神经系统及其作用,也随着物理学在二十世纪初的大发展之后的相对平静,很多物理学家开始插手其他学科。既然生命和非生命体的背后都服从同一套物理规律,既然物理学的众多成功经验说明,搞清楚构成系统的所有微观组成就可以理解宏观的系统,那么搞清楚人类的智力器官的基本单元以及相互作用,按理说也就能够理解什么是智慧。
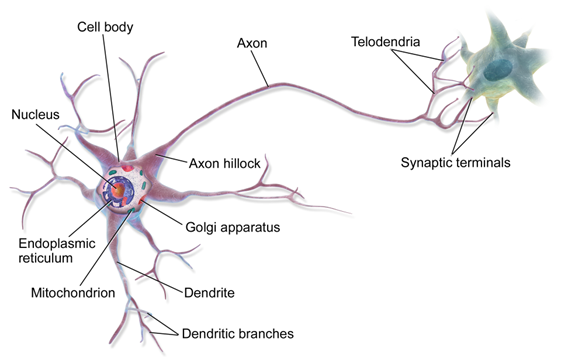
上图是一个神经细胞的结构示意图。从其他神经细胞释放出来的名为神经递质的化学物质,到达神经元左侧短且密集的树突之后,激活细胞膜表面的离子泵,主动运输离子跨过细胞膜,从而产生电信号。电信号沿细胞膜传导到右侧的树突,刺激凸触释放神经递质给下一个细胞。
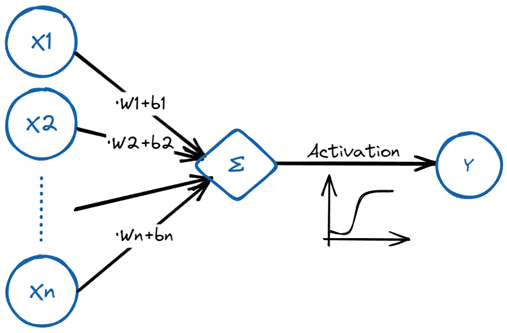
上图就是根据神经元的工作原理抽象出的数学模型,名为 perceptron。一个 perceptron 就是一个函数,接受多个输入的自变量,加权求和之后套一个非线性的激活函数,得到一个输出。很多个这样的 perceptron 并连和串联,就构成下图,计算机算法中的神经网络。
而从实验方向研究神经系统,我们隔壁系就有,经常来我们系招人。基本上就是在小鼠的天灵盖上锯开一个天窗,然后给它带上个头盔,头盔上有能从天窗伸进去的电极,采集脑神经的电信号。以前头盔有网线伸到实验室天花板,实时传到数据中心的超算。现在好像进步了,改用 Wi-Fi 了。
这实验怎么通过的伦理审查,咱也不知道,咱也不敢问……
管理学·DIKW “数据-信息-知识-智慧”模型
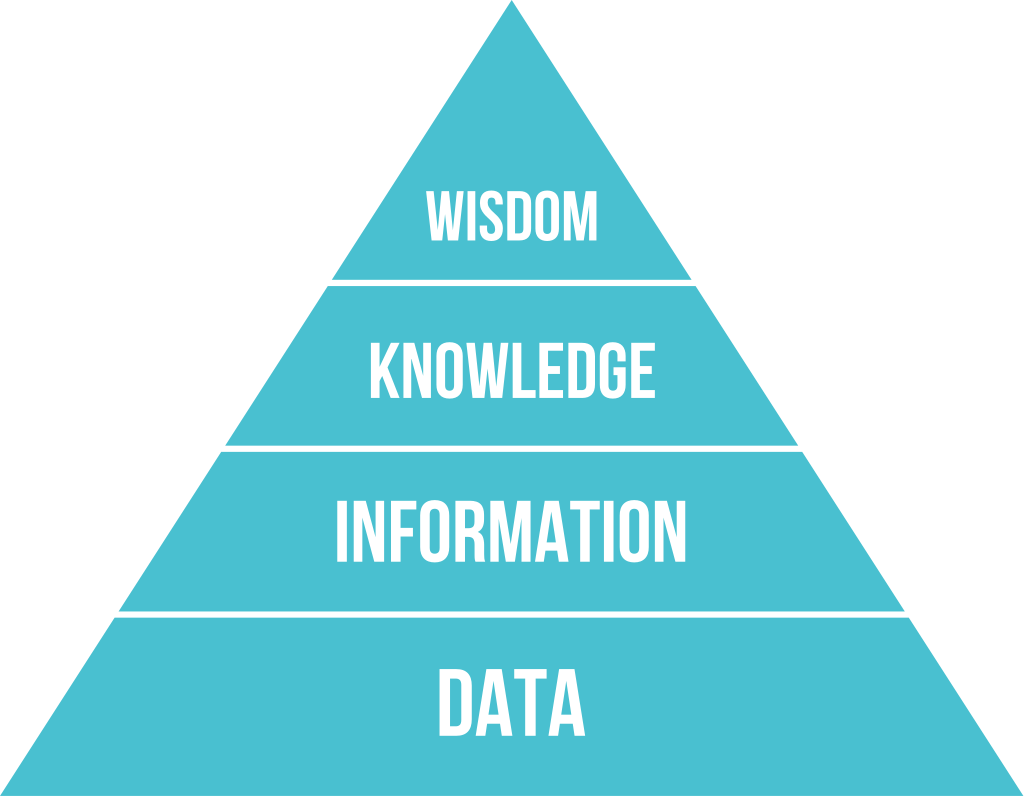
DIKW 四个字母分别代表 data, information, knowledge, wisdom,即数据、信息、知识、智慧,是一种知识管理中的心智模型。
四个层次,前一层都是后一层的基础,后一层都是对前一层的理解。
如果是书面文字,数据就是笔画和字母;如果是语言,数据就是人声的响度、频率和音色。由笔画/字母/声音组成的有含义的字词就是信息。表示信息之间的关系的,可以判断对错的命题就是知识。包含和统摄各条知识的思想体系,就是智慧。
反过来说,虽然智慧高于思想,但它仍需要通过把各条知识的表达汇总起来,才能被人感知。对知识的命题的理解依赖于构成名字的各个概念的涵义,属于信息水平的内容。而每个字都有不考虑其涵义的笔画字母构成。
这层与层之间看似并没有插入额外的内容,智慧可以直接由笔画构成。但是我们一层层理解的深入,其实是不自觉地借用了我们当前社会约定俗成的解读方式。
比如下面这个图片里的符号,对于现代人就只是数据,无法解读成信息。但是对于苏美尔人,这是用楔形文字表示的数字,是等腰直角三角形的腰和直角边的比值,也就是 的近似值。
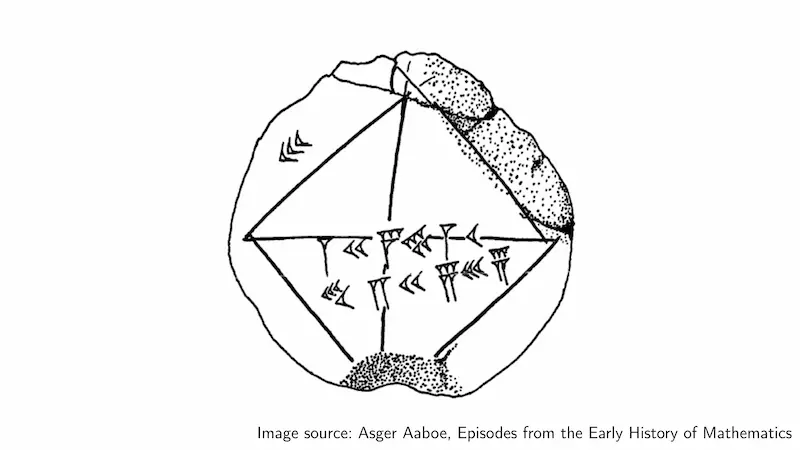
约定俗成的数据解读方式,也就是关于数据的数据,根据西方的构词法,可以叫做“元数据”(meta-data)。
数据和元数据一起构成信息,信息和元信息一起构成知识,知识和元知识一起构成智慧。俺坚持写博客的动机,就是用费曼学习法,把无意间使用的元知识显式地表达出来,而且记录下来,争取学而不退转。
2
回顾了这些,再来看大语言模型,就会发现它落在了各方努力的延长线的交点。
大语言模型里有一个重要概念叫做“嵌入”(embedding),就是把语言的基本字元 (token) 可逆地映射到一个超多维度的向量空间里。本来“国王”和“儿子”之间没办法加减乘除,但是嵌入后的向量空间里有加法和数乘,如果嵌入函数选得好,“国王”的向量 + “儿子”的向量,结果向量就约等于“王子”的向量。
生成式语言模型的核心就是一个超多元函数,接受前一个字嵌入后的向量作为输入,给出另一个向量作为输出,用嵌入函数的逆映射翻译成字元;再把旧的输出作为新的输入,直到输出结果是“语段结束”这样一个特殊字元为止。模型训练的过程,主要就是通过现成的语料,拟合这个超多元函数的参数。
从 DIKW 模型来看,语言模型操作的是最基本的数据,它的输出究竟是什么信息,是不是正确的知识,体现了多少智慧,是人根据当下的社会文化来解读的。
而实现 AI 的电子计算机,或是复杂生命的大脑,他们和智能之间的关系,应该就类似于具体的计算机电路和抽象语法树之间的关系。以此类比,未来的智能科学应该会成为一门独立的专业,它和计算机科学和神经生物学的区别,就像今天的电子科学与工程,和计算机科学之间的区别一样。当下神经生物学的热度,将来恐怕多半会被分流。
这种对字符的计算不同于逻辑运算,语言模型不判断输出结果在逻辑上的正确与错误,这既给了他啥都能说几句的 feature,又给了它经常编假消息的 bug。
想要改掉这种错误,引入对 AI 的纠错机制,治本之道恐怕还是诉诸于对世界的正确描述,与理论相关的还是要靠逻辑,与现实相关的还是要靠科学。
只不过,大语言模型提供了一种数据结构,有希望把人类已知的真理储存在一起。对这种数据结构本身的研究,有可能反过来启发科学的发展。柏拉图的洞穴之壁可能不再是一个比喻,未来更大的语言模型的,亿万维度的参数空间有希望成为洞穴门口的那团火。
只不过这一切都是“可能”,现在还只是 AI 的萌芽阶段,还没有足够的证据来证实或者证伪这种畅想。而且 AI 的参数量再大也是有限的,它所能表达的信息也就有限,而真理应当是无限的,就像科学一样,总要训练更新更大的模型,总要发现已知的未知,然后欣然接受更多未知的未知之存在。
如果电子计算机实现的 AI 独立于人类产生了意识和超出人类的智慧,很难想象他们会继续用人类语言这种对他们来说很不方便的方式来交流。
所以,哪怕是做个 AI 生成内容的质检员,科学家依然有事可做。这算是科学的堕落吗?当然不算,如果算的话,那从计算物理也被当作理论物理的那天起,人类就已经投降了(逃)
3
现在正面来回答问题:AI透過程式組合出回答你問題的文字組合,有「涵義」嗎?
答:有。
因为语言的「涵義」来自于语言的内容,和整个社会的文化,并不来自于这句话的作者的身份。即便是人与人之间的交流,诉诸身份也是一种非形式逻辑谬误,是理性不足的表现。只有在信息不足仍不得不下结论的时候才该使用,比如法律判决时的自由心证主义和/或法定证据主义。
而鹿妈眼里真人鹿酱与 AI 鹿酱的区别,如果有的话,好像主要体现在动机的区别。动机这种东西,很多智慧不高的生物,比如小猫小狗都会有;而现在的 AI,似乎还没有展现出超出编程者设计的动机。编程写入的信息有限,现有 AI 的动机也就有限,鹿酱的赢面还是很大的。
而动机是生物与非生物的区别吗?而什么是生物 ≠ 生物是什么,那就是另一个含混而复杂的问题了。
4
这篇博文发布的时候,高考应该已经结束了,马上该填报志愿了。
那么,西元 2023 年,AI 来袭的当下,该选个啥专业在 AI 浪潮中幸存,或者选个啥专业给 AI 老爷带路呢?

我的建议是,不要听别人的建议,按自己的兴趣来就好了。
刚刚改开的时候,有一个超级热门的专业,叫科技英语。科技落下了好多年,对外开放需要语言交流,两者一结合应该是热门又稀缺了。结果呢,你现在还听说过这个专业吗?
科技很重要是不错,语言很重要也不错,但是搞科技的人自己可以学英语,学英语的有几个搞得了科技?社会的进步主要靠创新,而创新的方向难以预测,不论这种预测分析听起来多有道理。
如果真的找不到兴趣,那就在能力范围之内,找个难度最高的。如果想从事智力劳动,那数学含量是个不错的衡量标准;如果不排斥体力劳动,那训练时间越长越值得考虑。
但这只是填志愿来不及时的权宜之计,发掘兴趣是人一生的课题。
兴趣不是为了让你成功的时候更得意,毕竟成功的话不论做什么都很得意;
兴趣是为了你不成功时也可以不失意,毕竟平凡才是人生的真谛。
本文收录于以下合集: